
목록Study/Interview준비 (59)
바위타는 두루미
문제 정수 배열에서 peak란 현재 원소가 인접한 정수보다 크거나 같을 때를 말하고, 'valley'란 현재 원소가 인접한 정수보다 작거나 같을 때를 말한다. 예를 들어 {5,8,6,2,3,4,6}이 있으면, {8,6}은 peak고 {5,2}는 valley인 것이다. 정수배열이 주어졌을때 'peak'와 'valley'가 번갈아 등장하도록 정렬하는 알고리즘을 작성하라. 해법 1. 부분 최적 해법 배열을 정렬하고 위치를 바꿈으로써 peak와 valley를 순차적으로 나올 수 있도록 만들 수 있을 것이다. 정렬된 배열 0 1 4 7 8 9 가 있다고 하자. 0은 올바른 위치고 1은 잘못 놓였다 0과 4중에 자리를 바꿀 수 있으나 0와 바꿔보자 7도 잘못 놓였다. 4과 8중에 자리를 바꿀 수 있으나 4과 바꿔보..
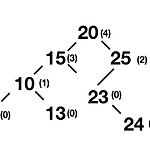 10.10 스트림에서의 순위
10.10 스트림에서의 순위
문제 정수 스트림을 읽는다고 하자. 주기적으로 어떤 수 x의 랭킹(x보다 같거나 작은 수의 갯수)를 확인하고 싶다. 해당 연산을 지원하는 자료구조와 알고리즘을 구현하라. 수 하나를 읽을 때마다 호출되는 메서드 track(int x)와, x보다 작거나 같은 수의 갯수( x자신을 제외)를 반환하는 메서드 getRankOfNumber(int x)를 구현하라 입력 : 5,1,4,4,5,9,7,13,3 출력 : getRankOfNumber(1) = 0 getRankOfNumber(3 ) = 1 getRankOfNumber(4 ) = 3 해법 모든 원소를 정렬된 상태로 보관하는 배열을 사용하면 구현하기가 상대적으로 간단해진다. 새로운 원소를 삽입할때마다 다른 원소들을 옆으로 옮겨 공간을 확보해야하는데 그렇다보면 t..
문제 각 행과 열이 오름차순으로 정렬된 MXN 행렬이 주어졌을대, 특정한 원소를 찾는 메서드를 구현하라 해결법 첫번째 : 행마다 이진탐색을 할 수있다. M개의 행이 있고 각 행을 탐색하는데 O(logN)이 걸리기 떄문에 O(MlogN)이 될 것이다. 두번재 해결법을 생각해보기 전에 규칙을 찾아보자 15 20 40 85 20 35 80 95 30 55 95 105 40 80 100 200 이런 행렬이 주어졌을때 55를 찾아보자. 행의 시작점이나 열의 시작점을 보면 위치를 유추해 볼 수 있다. 열의 시작점 원소의 값이 55보다 크다면 탐색할 필요가 없고, 마찬가지로 행의 시작점 원소의 값이 55보다 크다면 탐색할 필요가 없을 것이다. 그러면 행이나 열의 마지막점에서도 똑같이 적용할 수 있다. 어떤 행이나 열..
문제 음이 아닌 정수 40억 개로 이루어진 입력 파일이 있다. 이 파일에 '없는 정수'를 생성하는 알고리즘을 작성하라. 단, 메모리는 1GB만 사용할 수 있다. - 연관문제 메모리 제한이 10MB라면 어떻게 풀 수 있을까? 중복 되는 값은 없으며, 이번에는 정수가 10억 개만 있다고 가정하자. 접근법 우선 40억개라는 수의 의미를 알아야 했다. 40억개는 즉 2의 32승이 조금 안되는 수이다. 하지만 음이 아닌 정수라고 햇으니 2의 31개의 수가 40억개(2의 32승) 있다고 하니 중복되는 값이 있을 것이다. 제공된 메모리는 1GB => 2^30 *2^3 만큼의 비트를 사용할 수 있을 것이다. 따라서 2의 31 만큼의 수들을 모두 표현하기에 충분한 양이다. 따라서 1. 40억 비트의 크기인 비트벡터를 만..
문제 한 줄에 문자열 하나가 쓰여있는 20GB 짜리 파일이 있다고 하자. 이 파일을 정렬하려면 어떻게 해야할지 설명하라. 해결법 면접관이 20GB라는 제한을 준다는 것은 메모리에 모두 올릴 수 없다는 것을 의미한다. 바로 여기서 힌트를 얻는것이다. 가용 메모리의 크기가 x라고 가정했을때 파일을 x로 쪼개고 x 만큼씩 정렬하고 정렬이 끝나면 파일 시스템에 저장할 것이다. 모든 파일의 정렬이 끝나면 하나씩 병합한다. 모든 파일의 병합이 끝나 완벽히 정렬된 파일을 얻는다. 이런 알고리즘을 외부 정렬이라고 한다. 외부링크에 대한 참고링크 https://dudri63.github.io/2019/02/03/algo32/
문제 빈 문자열이 섞여 있는 정렬된 문자열 배열이 주어졌을때, 특정 문자열의 위치르 찾는 메서드를 작성하라. 입력 :"ball' , ["at", "" , "". "", "ball", "", "", "car", "" , "", "", "dad", "", ""] 해결법 빈 문자열이 없었다면 그냥 이진 탐색을 적용하면 될것이다. 이진 탐색을 적용하면서 빈 문자열에 대한 처리를 해주면 해결이 가능할 것이다. mid가 빈 문자열의 위치한 경우 가장 가까운 word의 위치를 mid로 변경해주고, 이진 탐색을 진행해 나가면 될 것같다. def Solution(list, target): if list is None or target=="" or target ==None : return -1 return findTarg..
문제 배열과 비슷하지만 size 메서드가 없는 Listy라는 자료구조가 있다. 여기에는 i 인덱스에 위치한 원소를 O(1) 시간에 알 수 있는 elementAt(i) 메서드가 존재한다. 만약 i가 배열의 범위를 넘어섰다면 -1를 반환한다. (이 때문에 이 자료구조는 양의 정수만 지원한다.) 양의 정수가 정렬된 Listy가 주어졌을때 원소 x의 인덱스를 찾는 알고리즘을 작성하라. 만약 x가 여러번 등장한다면 아무거나 반환하면 된다. 접근법 이것도 이진탐색법을 이용하면 문제가 해결될 것이다. 우선 배열의 size를 알려면 어떻게 하면 될까? 순차적으로 탐색을 할 수도 있지만 1,2,4,8,16 두배씩 늘려서 찾는다면 logN의 시간에 탐색이 가능할 것이다. 인덱스를 두배씩 늘리면서 탐색하다가 elementA..
문제 n개의 정수로 구성된 정렬 상태의 배열을 임의의 횟수만큼 회전시켜 얻은 배열이 입력으로 주어진다고 하자. 이 배열에서 특정한 원소를 찾는 코드를 작성하라. 회전 시키기 전, 원래 배열은 오름차순으로 정렬되어 있었다고 가정한다. 입력 : {15,15,19,20,25,1,3,4,5,7,10,14} , 5 출력 : 8 ( 배열에서 8번째 인덱스에 5가 있으므로) 접근법 이 문제를 보고 이진탐색을 생각했다면 매우 훌륭하다. 고전적인 이진탐색은 어떤 값 x가 왼쪽에 있는지 오른쪽에 있는지를 판단하기 위해 x를 배열의 중간 원소와 비교한다. 하지만, 이 문제는 배열이 회전된 상태라서 까다롭다. 두 배열을보자 배열 1 {10,15,20,0,5} 배열 2 {50,5,20,30,40} 이 두배열 모두 20이 가운데..
문제 Anagram 묶기: 철자 순서만 바꾼 문자열이 서로 인접하도록 문자열 배열을 정렬하는 메서드를 작성하라. 해결법 두 문자열이 철자 순서만 바꾼 문자열이라는 사실을 알아내려면 어떻게 할 수 있을까? 1. 정렬해서 같은 글자라면 Anagram일 것이다. 2. 나오는 철자들의 갯수를 세서 같은 갯수면 Anagram일 것이다. 첫번째 방식을 이용해서 해결이 가능할 것같다. 정렬한 값을 key로 문자열을 해쉬의 벨류로 가지는 해쉬를 관리함으로써 해결이 가능할 것이다. def getAnagrams(words): sortChars = {} for w in words: key = ''.join(sorted(w)) sortChars[key] = sortChars.get(key, []) + [w] result = ..
문제 0(false), 1(True), &(and), |(or), ^(xor)로 구성된 불린 표현식과 원하는 계산 결과가 주어졌을때 , 표현식에 괄호를 적절하게 추가하여 그 값이 원하는 결과값과 같게 만들 수 있는 모든 경우의 갯수를 출력하는 메서드를 구현하라. 접근법 1. 무식한 방법 표현식이 0^0&0^1|1이고 원하는 결과가 true인 경우를 생각해보자, countEval( 0^0&0^1|1, true)를 어떻게 쪼갤 수 있을까? countEval( 0^0&0^1|1, true) = countEval( 0^0&0^1|1 괄호가 1번 위치에 있을때 , true) + countEval( 0^0&0^1|1 괄호가 3번 위치에 있을때 , true) + countEval( 0^0&0^1|1 괄호가 5번 위치..